
At AI Signals x LangChain Community London #32, Sofía Sánchez-Zárate from CopilotKit gave a talk titled “AG-UI & The Generative UI Spectrum.” The demo that stuck with me: you ask for help working out a loan repayment, and instead of answering with a single number — one you’d have to ask it to recompute every time you change the rate or the term — it renders an actual working calculator inside the chat. Inputs you can edit, a total that updates live. Not a screenshot of one; a real widget the agent assembled for that question, on the fly.
That is generative UI: the chat stops being a text box and becomes a surface the agent can compose.
I’ve already been building this — by hand
The reason the talk landed is that I’ve been collaborating on a conversational KYC project that does exactly this. The agent doesn’t answer onboarding questions with paragraphs. When it needs a beneficial-ownership structure, it renders a form to add people and their relationship to the company. When it has extracted data from an uploaded document, it shows an editable confirmation panel, not a wall of text. It renders file uploads, a signature pad, a shareholder chart — all in the conversation.
Under the hood, the pattern is straightforward. The agent (built on LangGraph) pauses with a typed interrupt — a payload whose type is person_form, confirm_summary, signature_pad, shareholder_chart, and so on. The React front end keeps a registry that maps each type to a component, renders it, lets the user interact, and sends the result back so the graph resumes from exactly where it paused.
It works really well. It is also entirely homegrown and welded to our stack: our interrupt format, our widget registry, our front end. Which is precisely why Sofía’s talk hit — what we built vertically by hand is the thing AG-UI standardises.
What AG-UI actually is
AG-UI (Agent-User Interaction) is a lightweight, event-based protocol for the channel between an agentic backend and the front end a human looks at. Instead of returning one final text blob, the agent emits a stream of typed events the UI renders as they arrive:
- Lifecycle —
RunStarted,RunFinished,RunError, with optionalStepStarted/StepFinishedpairs. - Text messages — streamed token by token.
- Tool calls — so the UI can show what the agent is doing.
- State — snapshots plus deltas to keep front end and agent in sync.
Our interrupt-plus-registry mechanism is a private dialect of this. AG-UI is the attempt to make it a shared language — so a conversational backend isn’t permanently married to one bespoke front end, and so human-in-the-loop (pause, let the user confirm or edit or sign, resume) is a native primitive rather than something you wire up yourself.
The generative UI spectrum
The framing I found most useful was the spectrum — how much of the interface the model dictates, from least to most:
- Typed components. The agent picks from a fixed catalogue of front-end components and fills them with data. This is exactly what our KYC widgets are: the model doesn’t invent the form, it chooses
person_formand populates it. - Declarative UI. The agent emits a description of the interface and the client renders it. A2UI (Google’s spec) streams a UI tree as JSONL — a serialised layout of components and bindings the client builds, rather than a fixed catalogue the client already has. Open-JSON-UI (OpenAI) is the same idea from the other camp; it’s the lineage behind the interactive charts ChatGPT has started rendering inline — an equivalent protocol, though not strictly the one CopilotKit proposes. (Worth clearing up a common confusion: A2UI is not AG-UI. A2UI is one UI representation; AG-UI is the transport that can carry it.)
- Iframe-embedded. MCP-UI ships self-contained UI inside a sandboxed frame.
- Generated pixels. At the far end, the model renders the interface itself — the territory I explored in Software Is Dissolving Into the Model, where Flipbook and Project Genie generate every frame with no DOM at all.
AG-UI’s bet is to be the neutral pipe across that whole range: standardise the channel, and let the representation slide from typed → declarative → generated without rewriting the backend each time. The generated-pixel end is where I’d previously argued software is heading; generative UI is the pragmatic middle of the same line — structured enough to be reliable, generated enough to be flexible.
Why forms are the killer case
Sofía pointed out that conversational AI over forms is where this shines — and that DocuSign, whose entire business is documents, agreements and signatures, has a partnership with CopilotKit. That clicked immediately, because forms are exactly where plain text falls apart.
A conversation is a great way to gather information and a terrible way to structure it. “List every shareholder with more than 25%, their nationality, and their relationship to the directors” is painful as a back-and-forth of messages and trivial as a small rendered table you fill in. Confirming fields pulled from a passport, drawing a signature, reviewing an ownership tree — none of that wants paragraphs; it wants widgets. That’s the whole premise of the KYC project: replace the rigid step-by-step wizard with a conversation that still produces structured, validated, signable data. Generative UI is what makes the conversation and the structure the same surface.
What standardising would buy
Our homegrown protocol works, but it’s coupled. A standard like AG-UI would let the same conversational backend talk to any front end that speaks it, mix in declarative UI specs where a fixed widget catalogue is too rigid, and get human-in-the-loop pauses as a first-class part of the protocol instead of a convention we maintain. The cost is the usual one for adopting a young standard: betting on its event model and its trajectory.
Given that LangGraph — which our project already runs on — is among the frameworks with AG-UI integration, the migration path from “our dialect” to “the standard” is unusually short. That makes it a real option, not a rewrite.
Trying it: from hand-built pattern to SDK
To feel the difference between my bespoke version and the standard, I built a tiny demo with the AG-UI SDK — a Pydantic AI agent on Azure OpenAI, a CopilotKit React frontend, and the two widgets declared as frontend tools. Ask it to estimate a loan repayment and it renders an interactive calculator in the chat; say you want to apply and it renders a form. The Python side is essentially “wire a model to AG-UI” — the generative UI lives on the client, in about a hundred lines total.
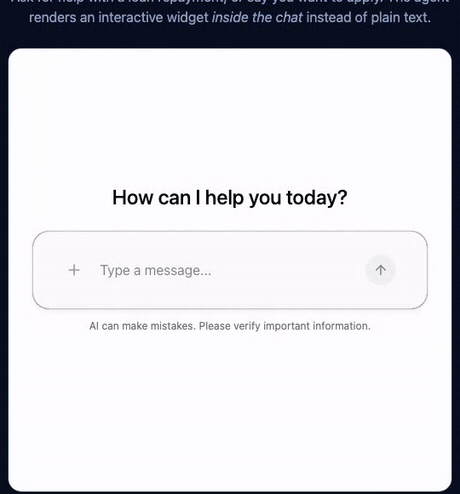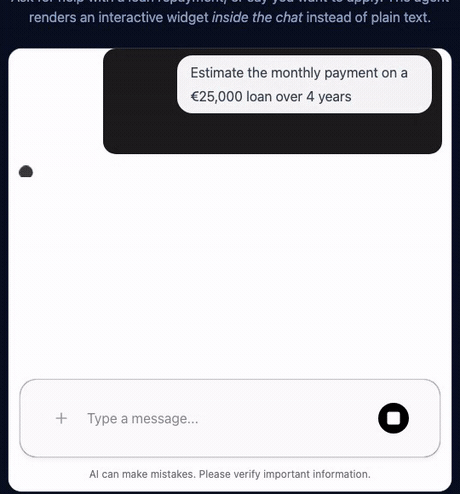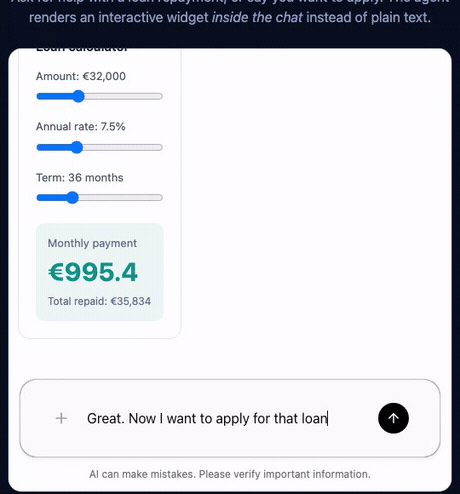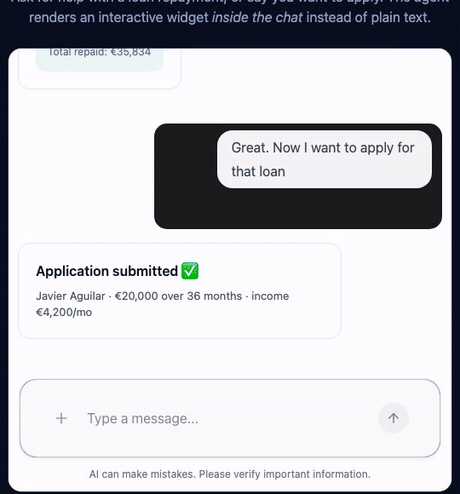
That’s the whole point in one screen: the same loop as the KYC project — model picks a widget, client renders it, the user interacts, the result flows back — but the wiring is a protocol instead of a registry I maintain by hand. Code on GitHub.
The middle of the spectrum
The honest takeaway is that generative UI answers a question I left open in Software Is Dissolving Into the Model: if the rendered surface is drifting from hand-coded components toward model-generated pixels, where do you stand today, on a product that has to actually work? The answer is the middle of the spectrum — let the model choose and compose structured UI, keep the rendering reliable — and a protocol like AG-UI is what lets you pick your spot on that line and move along it later. I’ve been standing there by hand for months. It’s good to see it getting a name.
Inspired by Sofía Sánchez-Zárate’s talk “AG-UI & The Generative UI Spectrum” at AI Signals x LangChain Community London #32. Protocol details: the AG-UI docs and the AG-UI Dojo. Related reading: Software Is Dissolving Into the Model.