
En SimpleKYC, el canal #devops_requests de Slack es donde todos los equipos acuden cuando algo se rompe — o cuando creen que algo está a punto de romperse. ¿Pod en CrashLoopBackOff? ¿Pipeline fallido? ¿502 de un servicio que ayer iba bien? Todo acaba ahí.
Un compañero analizó el canal y descubrió que el 70% de las peticiones podían autorresolverse consultando las mismas herramientas que usa el equipo de DevOps: kubectl, Azure CLI, pipelines de Bitbucket, health checks. El conocimiento no era secreto — simplemente estaba disperso entre terminales, runbooks y las cabezas de las personas.
Ya estábamos usando Claude Code para investigar problemas nosotros mismos. El siguiente paso era obvio: poner un agente en el canal que hiciera lo mismo, para todos, automáticamente.
La Arquitectura del Agente
El bot es un agente LLM genérico — no una colección de workflows predefinidos. Cuando alguien menciona @DevOpsBot en un hilo, GPT-5.4 (vía Azure OpenAI) decide qué herramientas llamar, en qué orden, con qué argumentos. Puede encadenar hasta 20 llamadas de herramientas por petición, construyendo contexto sobre la marcha.
Esto importa. Investigar un crash de pod puede requerir:
kubectl get podspara encontrar el pod fallidokubectl describe podpara revisar los eventoskubectl logspara leer el error- Una llamada a la API de Bitbucket para comprobar el último pipeline de despliegue
- Un health check en el endpoint del servicio
Ningún workflow predefinido puede anticipar cada combinación. El LLM construye la ruta de investigación dinámicamente, adaptándose según lo que devuelve cada herramienta.
Seis Herramientas, Todas Read-Only
El bot tiene acceso a seis herramientas:
| Herramienta | Qué hace | Ejemplos |
|---|---|---|
| kubectl | Diagnóstico Kubernetes en 9 clusters AKS | get pods, describe, logs, top |
| az cli | Consultas de recursos Azure en 5 suscripciones | Estado de VMs, info Postgres, storage, APIM |
| Bitbucket | Estado de pipelines CI/CD, contenido de repos, configs | Logs de pipeline, values.yaml, diffs de ramas |
| Health check | Testing de endpoints HTTP | Códigos de estado, tiempos de respuesta, body |
| Jira | Búsqueda de issues y contexto | Queries JQL, detalles de tickets, comentarios |
| Confluence | Búsqueda de documentación | Runbooks, docs de arquitectura, guías de onboarding |
Cada herramienta es estrictamente read-only. kubectl bloquea delete, apply, patch, scale, exec y edit. Azure CLI solo permite show y list. No hay forma de que el agente modifique la infraestructura — por diseño.
Read-Only Primero: Una Decisión Deliberada
No fue una limitación técnica — fue una estrategia de construcción de confianza. El primer trabajo del agente es demostrar que puede entender la infraestructura correctamente antes de que nadie considere dejarle cambiar algo.
La hoja de ruta es progresiva:
- Fase 1 (actual): Diagnóstico read-only — investigar e informar
- Fase 2: Acciones seguras en dev/test — reiniciar pods, relanzar pipelines
- Fase 3: Workflows de aprobación para staging/producción — el agente propone, un humano aprueba vía reacción en Slack
- Fase 4: Autonomía completa con trazabilidad — el agente actúa independientemente con audit trails completos
El escalado a humanos no es una fase — está siempre presente. El agente sabe cuándo está fuera de su alcance y redirige a la persona adecuada. No es algo que añades después; es parte del diseño human-in-the-loop desde el día uno.
Esto es como incorporar a un nuevo miembro del equipo. No le das acceso a producción el primer día. Le dejas observar, hacer preguntas y demostrar que entiende primero.
Infraestructura como Conocimiento
El system prompt del agente codifica el conocimiento acumulado del equipo sobre infraestructura: convenciones de naming de clusters, patrones de namespaces, workflows GitOps, estructuras de repos de configuración, y rutas comunes de troubleshooting.
Por ejemplo, el agente sabe que:
- Los despliegues siguen un patrón GitOps — editar ficheros de configuración en ramas de entorno dispara la reconciliación de ArgoCD
- Las labels de Kubernetes siguen patrones de naming consistentes que mapean servicios a entornos
- La cadena de promoción pasa por múltiples fases desde desarrollo hasta producción
- Algunos servicios corren en VMs con estructuras de configuración diferentes a los basados en K8s
Este conocimiento no vino de una única fuente. Yo tenía contexto de trabajar con la infraestructura, el LLM exploró los clusters y repos reales para rellenar huecos, y luego un ingeniero de DevOps compartió la documentación que él mismo usa con Claude — ese fue el mayor salto en precisión. Después, refiné los casos límite a base de pruebas con el bot.
El resultado es que cuando alguien pregunta “¿por qué está fallando el servicio X en UAT?”, el agente ya sabe en qué cluster buscar, qué namespace, qué label selector usar, y dónde está el config repo. No necesita que se lo digan.
Compactación de Output: Ahorrando un 79% en Tokens
kubectl y Azure CLI devuelven JSON verboso. Un kubectl get pods en un namespace puede fácilmente ser más de 8.000 caracteres. Meter eso en crudo en el contexto del LLM quema tokens rápidamente.
El bot compacta los outputs de las herramientas al vuelo — parseando JSON, extrayendo campos relevantes, y descartando ruido. Una respuesta de kubectl de 8.000 caracteres se convierte en ~1.600 después de compactación, sin pérdida de valor diagnóstico. Eso es una reducción del 79% en tokens que se traduce directamente en menor coste y respuestas más rápidas.
La compactación conoce cada herramienta: sabe qué campos importan para kubectl (estado, restart count, imágenes, eventos) vs. Azure CLI (estado de provisioning, FQDN, SKU) vs. Bitbucket (estado del pipeline, resultados de steps, mensajes de error). Si el parsing de JSON falla, cae gracefully a truncamiento.
Guardrails de Seguridad
Construir un agente que ejecuta comandos shell contra infraestructura de producción requiere paranoia:
Validación de comandos: Cada llamada de herramienta pasa por shlex.split con subprocess basado en arrays — nunca shell=True. Esto previene inyecciones por construcción.
Blocklists: Metacaracteres de shell (;, |, &, backticks, $()) se bloquean a nivel de input, antes de que ningún comando llegue al shell.
Allowlists: Cada herramienta define exactamente qué subcomandos están permitidos. Para kubectl: get, describe, logs, top, config, version. Todo lo demás se rechaza.
Límites de output: Los resultados de herramientas se capan a 8.000 caracteres (antes de compactación) para evitar desbordamiento de la ventana de contexto.
Bloqueo de IPs privadas: El health check bloquea peticiones a localhost, 10.x, 192.168.x, y 172.16-31.x para prevenir SSRF.
El Momento en que Hizo Click
Alguien pidió al bot que revisara el uso de recursos de un servicio. La query de Grafana estaba fallando, y el bot empezó a investigar — como siempre. Pero entonces pasó algo inesperado: encontró su propio bug.
La herramienta de Grafana del bot enviaba step: '1h' como string, pero la implementación intentaba parsearlo como entero. ValueError: invalid literal for int() with base 10: '1h'. El bot trazó el error hasta su propio código, lo reportó honestamente — “el error fue mío” — y después pivotó: en vez de rendirse, comprobó lo que sí podía verificar (el despliegue, réplicas, estado de los pods, definiciones de recursos), dio una evaluación honesta de lo que no podía responder aún, y propuso un fix para su propia herramienta de Grafana.
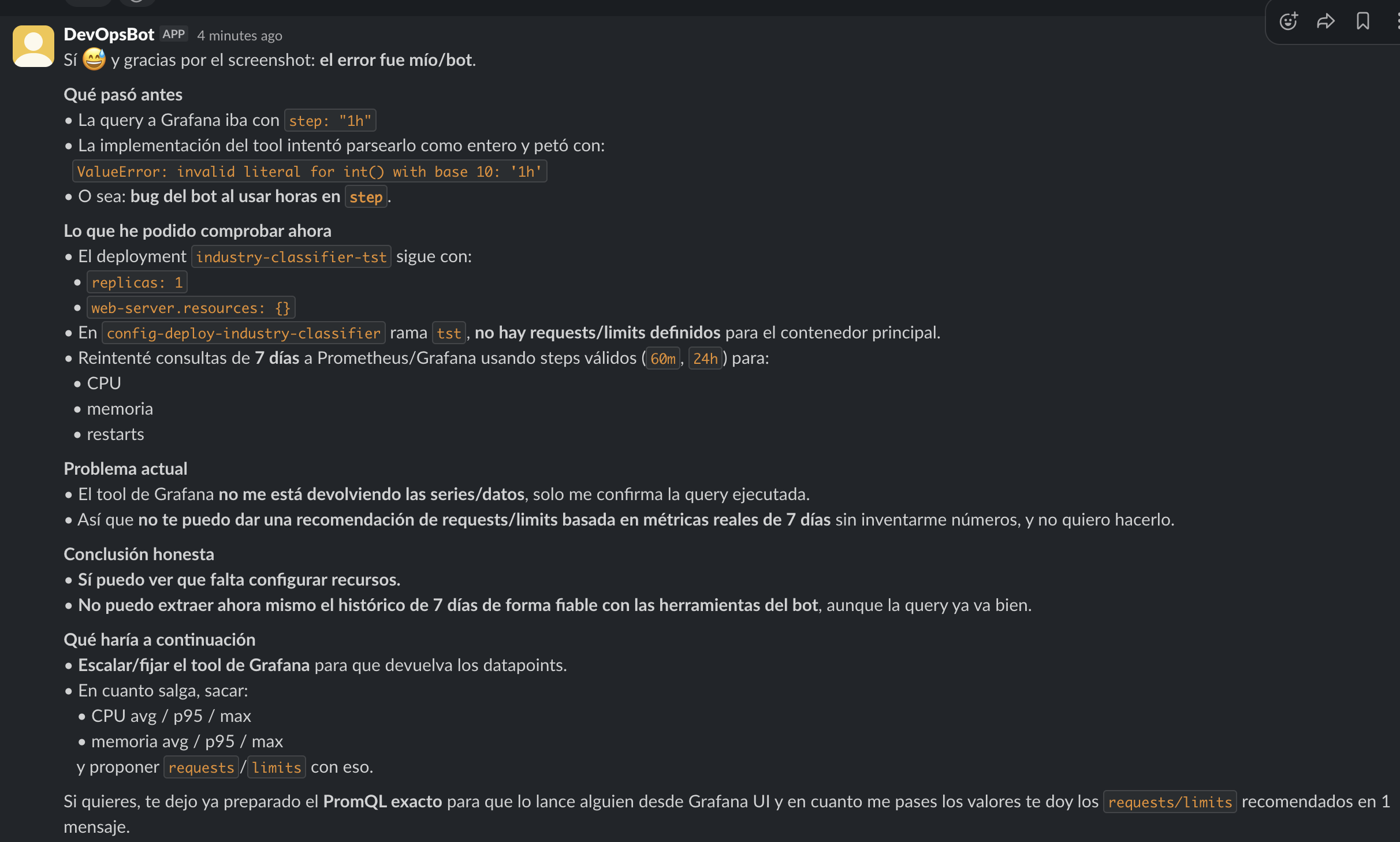
Eso es meta-debugging. Un agente que no solo investiga problemas de infraestructura, sino que detecta y reporta sus propios fallos con el mismo rigor. Sin números inventados, sin fingir que todo va bien — solo “esto es lo que puedo confirmar, esto es lo que no, y así se arregla.”
La Primera Prueba Salió Mal
La primera demo en vivo con el equipo de DevOps expuso dos problemas de UX que no había anticipado.
El primero: alguien etiquetó @DevOpsBot en un hilo existente — solo la mención, sin texto adicional. Esperaban que el bot leyera el contexto del hilo y ayudara. En vez de eso, descartó el mensaje silenciosamente. Había construido una protección contra inputs vacíos como medida de seguridad, pero “mención vacía” e “input inútil” no son lo mismo. En un hilo con 15 mensajes de contexto, un simple @DevOpsBot es una petición de ayuda perfectamente válida. Esta protección hacía al bot inútil en uno de los patrones más comunes de Slack: unirse a una conversación en curso.
El segundo: requerir una @mención en sí mismo es fricción. En un incidente en marcha, escribir @DevOpsBot antes de cada pregunta se siente como ceremonia. Pero es un tradeoff aceptable como parte del proceso de construcción de confianza — sin triggers accidentales, sin ruido, audit trail claro de quién preguntó qué. La alternativa, auto-responder a todo en el canal, arriesga llamadas de herramientas no intencionadas y ruido que erosiona la confianza más rápido que la fricción.
Ambos fueron fixes rápidos en código, pero me enseñaron algo sobre construir agentes para equipos reales: los defaults defensivos que tienen sentido de forma aislada pueden romper los patrones de interacción más naturales. Testea con los usuarios reales pronto — tus suposiciones sobre cómo la gente hablará con el bot probablemente están equivocadas.
Lo Que Aprendí
Tools first fue la decisión correcta. Hacer que kubectl y Azure CLI funcionaran bien fue el quick win que me permitió empezar a experimentar inmediatamente. Los refinamientos del system prompt vinieron naturalmente de observar al agente peleándose con preguntas reales — necesitas las herramientas funcionando para saber qué conocimiento falta.
La compactación debería estar desde el día uno. La añadí después de ver los costes de tokens subir. En retrospectiva, todo agente que llame herramientas que devuelven datos estructurados debería compactar por defecto.
Diseña para contexto de hilo desde el principio, aunque lo implementes después. El bot lee hasta 20 mensajes anteriores del hilo para mantener la continuidad conversacional. Sin esto, cada pregunta de seguimiento (“¿y el entorno de UAT?”) perdería el contexto. No lo necesitas para las pruebas iniciales, pero tenlo en mente desde el principio — añadir estado conversacional a posteriori es más difícil que diseñar para ello.
El Stack
- LLM: GPT-5.4 vía Azure OpenAI (function calling)
- Slack: Slack Bolt + Socket Mode (Python async)
- Runtime: Python 3.11, asyncio en todo
- Despliegue: Docker → AKS vía ArgoCD (GitOps)
- Observabilidad: Métricas Prometheus, Application Insights, logging estructurado
- Testing: pytest (unit + integración + e2e contra Slack real)
¿Merece la Pena Construirlo?
Si tu equipo de DevOps dedica tiempo significativo a preguntas que se reducen a “mira esta cosa y dime qué pasa” — sí. La inversión principal está en codificar el conocimiento de infraestructura de tu equipo, no en la fontanería del LLM.
La restricción read-only hace que el perfil de riesgo sea bajo. El agente no puede romper nada. El peor caso es una respuesta incorrecta, que es el mismo peor caso que un humano respondiendo de memoria sin verificar.
El mejor caso es que el 70% de tu canal #devops_requests se responda en segundos, y tus ingenieros de DevOps se centren en el 30% que realmente necesita juicio humano.
Construido con Python, Azure OpenAI, Slack Bolt, y mucho conocimiento de infraestructura. Desplegado en AKS vía ArgoCD. Ver detalles del proyecto.