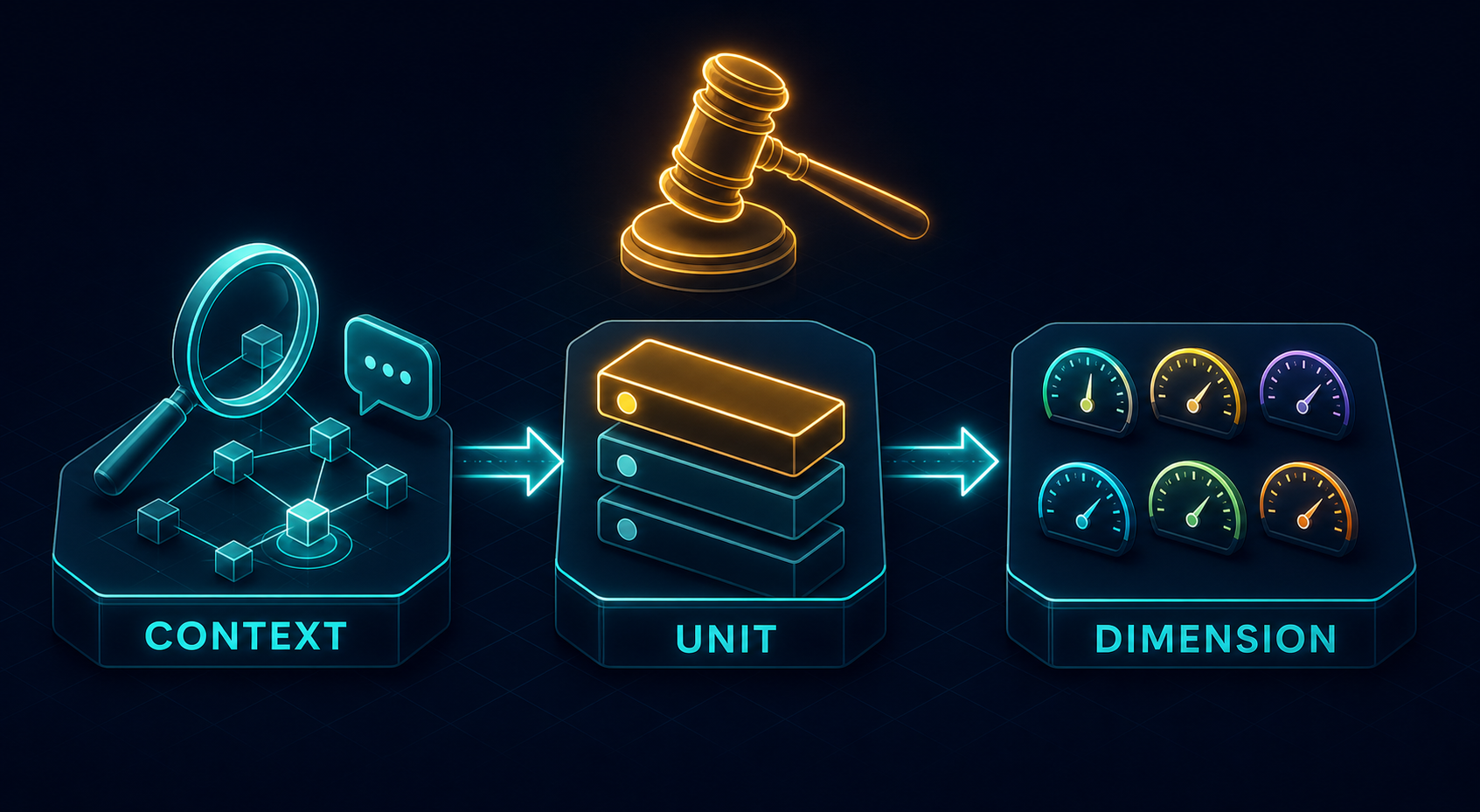
La semana pasada fui al AI Signals x LangChain Community London #32, y una idea de la charla de Bilge Aksu sobre evaluación lleva dándome vueltas desde entonces. La puso en una diapositiva que decía “Context comes first” (el contexto va primero), con un subtítulo que no dejo de citar: ni siquiera puedes elegir la unidad correcta ni la dimensión correcta hasta que conoces el contexto.
Esa frase me cambió la forma de pensar el LLM-as-judge. Solemos tratar “usar un LLM para puntuar respuestas” como un problema de prompt engineering: escribe una buena rúbrica, pide una nota del 1 al 10, parsea el número. Pero un juez que produce un número no es lo mismo que un juez que produce un número útil. Lo útil se decide mucho antes del prompt, en tres elecciones que la mayoría hace de forma implícita y, por tanto, hace mal.
La trampa: una nota que nadie validó
Este es el modo de fallo que describió Bilge y que más me caló. Tu juez dice que una conversación fue “buena”, pero el usuario no volvió nunca. O marca una conversación como “mala”, y resulta que ese usuario es tu cliente más fiel. Los criterios del juez y la señal real de los usuarios apuntan en direcciones opuestas.
Cuando eso pasa, el instinto es retocar la rúbrica. El problema de verdad suele estar más arriba: el juez puntuaba la unidad equivocada, en la dimensión equivocada, con muy poco contexto para saberlo. Una nota de “calidad general” del 1 al 10 esconde los tres errores detrás de un único entero de aspecto seguro.
Así que antes de escribir una sola línea del prompt del juez, ahora me obligo a pasar por tres decisiones, en orden.
Decisión 1 — Contexto: la situación, decidida primero
El contexto es lo que el juez puede ver, y es lógicamente previo a todo lo demás. ¿Quién es el usuario? ¿Qué tipo de petición es esta? ¿Qué información había realmente disponible cuando se produjo la respuesta?
Un juez con el contexto equivocado se equivocará con total seguridad. Si pregunto “¿fue correcto este diagnóstico?” pero solo le enseño al juez el mensaje final del chat —no los logs, no las salidas de las herramientas que el agente realmente vio—, entonces el juez está puntuando prosa, no corrección. Premiará una respuesta fluida y plausible por encima de una escueta y acertada.
Acertar con el contexto significa decidir deliberadamente: ¿ve el juez la pregunta original, los documentos recuperados, las llamadas a herramientas y sus resultados, el hilo completo? Cada uno de esos es una palanca, y dejarlas en su valor por defecto (“solo la salida”) es como acabas con notas que correlacionan con la verbosidad en lugar de con la verdad.
Decisión 2 — Unidad: un turno, una conversación, o entre sesiones
La unidad es qué puntúas. El mismo sistema se puede evaluar con tres granularidades muy distintas, y responden a preguntas diferentes:
| Unidad | Qué responde | Buena para |
|---|---|---|
| Turno (one-shot) | ¿Fue correcta esta respuesta individual? | Preguntas con respuesta clara y verificable |
| Conversación (hilo) | ¿La interacción completa alcanzó el objetivo? | Resolución iterativa de varios pasos |
| Sesión / entre sesiones | ¿Se resolvió el problema de fondo del usuario con el tiempo? | Retención, confianza, resultado real |
Esta distinción se volvió concreta cuando empecé a evaluar mi agente de DevOps en producción — un bot de Slack que tría preguntas de infraestructura consultando herramientas reales (Kubernetes, CLIs de cloud, CI/CD, logs).
Algunas de sus peticiones son genuinamente one-shot: “¿dónde encuentro los logs del servicio X?” tiene una respuesta correcta, y un juez a nivel de turno es la unidad adecuada — ¿apuntó al sitio correcto, sí o no? Otras son iterativas: una investigación de un error 500 que se lleva diez rondas de razonamiento y una docena de llamadas a herramientas. Puntuar ahí solo el turno final tira a la basura la información más importante — el cómo llegó hasta ahí.
Y una tercera categoría no es realmente un juicio de calidad. El número de llamadas a herramientas, el tipo de llamada, el uso de tokens, el número de rondas de razonamiento, el tiempo de respuesta — son métricas de eficiencia. Van en su propio eje, no mezcladas en una nota de “calidad”. Confundir “fue correcto” con “fue barato” es una de las formas más rápidas de producir un número sin sentido.
Decisión 3 — Dimensión: qué aspecto de “bueno”
La dimensión es qué propiedad estás midiendo. “Bueno” no es una sola cosa — es exactitud, utilidad, calidez, seguridad, concisión y una docena más, y se compensan entre sí. Un único juez que puntúa “bueno en general” está promediando en silencio propiedades incompatibles.
El arreglo es aburrido y eficaz: un juez, una dimensión, idealmente un veredicto binario más una crítica escrita breve en lugar de un número en una escala. “¿Es esto factualmente correcto? sí/no, y por qué” te da algo accionable y auditable. “Puntúa la calidad del 1 al 10” te da ruido con un decimal.
Juntándolo todo: evaluar el agente de DevOps
Cuando validé el agente de DevOps contra el histórico real de soporte, las tres decisiones hicieron la evaluación legible en vez de vaga.
Contexto: tomé peticiones reales de un canal interno de soporte y le di al juez el hilo de resolución humana original junto a la respuesta del bot — para que comparara lo comparable, no que puntuara al bot en el vacío.
Unidad: por petición (a nivel de turno las one-shot, a nivel de hilo las investigaciones), más una vía de eficiencia separada.
Dimensión: primero corrección (¿es correcta la respuesta?), luego exhaustividad (¿encontró lo que encontró el humano — o más?), con la eficiencia en su propio eje.
Los números principales, sobre diez casos reales:
| Métrica | Valor |
|---|---|
| Respuestas correctas | 10/10 (100%) |
| Mejor que la resolución humana | 6/10 (60%) |
| Peor que el humano | 0/10 |
| Tiempo medio de respuesta | ~2,5 min frente a horas/días del ciclo humano |
Después desplegué un sistema de memoria persistente y reejecuté los mismos diez casos como benchmark antes/después — y aquí es donde mantener la eficiencia en su propio eje dio fruto. La calidad (corrección) se mantuvo plana en el 100%, que es exactamente lo que quieres: el cambio no debía hacer las respuestas más correctas, debía hacerlas más baratas de producir. En ese eje la mejora fue clara — el tiempo total cayó un 57%, y un caso de “respuesta conocida” pasó de 16 llamadas a herramientas a 2 (unas 7× más rápido) porque el bot recordó la respuesta en vez de reinvestigar. Dos casos no mejoraron, y uno sobre-investigó — algo que las métricas de eficiencia destaparon al instante, donde una nota de “calidad” mezclada lo habría escondido.
La dimensión que olvidaste validar
Volvamos a la trampa de Bilge, porque mis propios números la contienen. “Mejor que el humano en el 60% de los casos” — ¿mejor en qué dimensión, y quién lo decidió? Lo decidí yo, leyendo hilos, usando mi propio criterio como rúbrica. Es un punto de partida perfectamente válido. No es lo mismo que la dimensión que de verdad importa en producción: ¿la persona que preguntó se desbloqueó y confió en la respuesta lo suficiente como para actuar?
Ese hueco —entre el criterio que tu juez optimiza y el resultado que tus usuarios realmente viven— es el juego entero. Las tres decisiones no lo cierran por ti. Lo que hacen es volverlo visible: cuando has nombrado tu contexto, tu unidad y tu dimensión de forma explícita, puedes señalar exactamente cuál se está alejando de la realidad, en lugar de mirar fijamente un único número preguntándote por qué no concuerda con tu gráfico de retención.
Una checklist antes de escribir el prompt del juez
- Contexto — ¿Qué ve exactamente el juez? ¿Tiene todo lo que necesitaría un evaluador justo, y nada que solo premie la fluidez?
- Unidad — ¿Estoy puntuando un turno, una conversación o una sesión? ¿Coincide con la pregunta que de verdad estoy haciendo?
- Dimensión — Una propiedad por juez. ¿Se está colando la “eficiencia” en mi nota de “calidad”?
- Forma del veredicto — Binario + crítica antes que una escala del 1 al 10, siempre que pueda.
- Validación — ¿He contrastado el juez con una señal del mundo real (etiquetas humanas, retención, si volvieron) — o estoy confiando en un número que nadie validó?
El prompt es el último 10% de construir una buena eval. El primer 90% es decidir qué estás midiendo, sobre qué, y con qué a la vista. El contexto va primero.
Inspirado por la charla de Bilge Aksu en AI Signals x LangChain Community London #32. El agente de DevOps al que se aplica está descrito aquí. Para leer más: la guía de LLM-as-judge de Hamel Husain y el paper de MT-Bench que arrancó el campo.