Tienes un millón de tokens de texto. La ventana de contexto de tu modelo es de 128K. ¿Qué haces?
Las respuestas habituales son RAG (trocear, generar embeddings, recuperar los fragmentos relevantes) o modelos de contexto largo (esperar que la ventana sea suficiente). Pero ambos tienen trade-offs fundamentales: RAG pierde contexto global porque solo recupera fragmentos, y los modelos de contexto largo degradan su calidad a medida que crece la entrada — el famoso problema “lost in the middle”.
Un paper reciente de arXiv propone un tercer enfoque: Recursive Language Models (RLM). La idea es engañosamente simple — dejar que el LLM programe su propio acceso al documento.
Construí un prototipo funcional. Así es como lo hice.
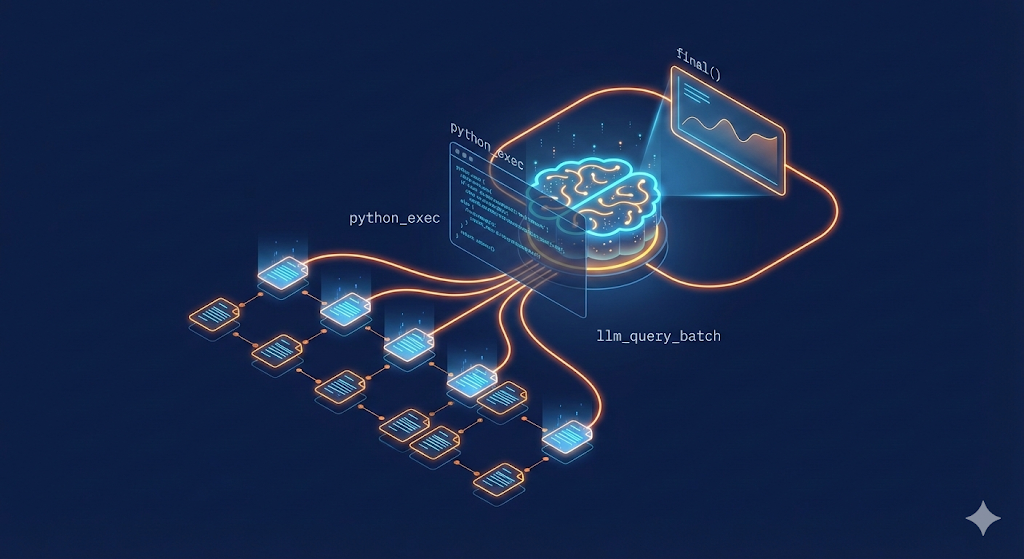
¿Qué es un Recursive Language Model?
El paper RLM introduce un paradigma de inferencia donde el modelo trata un documento largo como un entorno externo en lugar de como entrada. En vez de meter el texto en el prompt, el sistema:
- Carga el documento en memoria (un entorno Python) donde el modelo no puede verlo directamente
- Le da herramientas al modelo para examinar, hacer slicing y buscar en el documento mediante ejecución de código
- Permite sub-llamadas recursivas — el modelo puede invocarse a sí mismo sobre fragmentos para resumirlos o analizarlos
Esto es fundamentalmente diferente de RAG. En RAG, un sistema de recuperación decide qué es relevante antes de que el modelo vea nada. En RLM, el propio modelo decide qué leer, cuándo y con qué profundidad — escribe código Python para navegar el texto.
La clave: los LLMs son sorprendentemente buenos escribiendo código para explorar datos que no pueden ver. Buscan patrones, hacen slicing alrededor de regiones interesantes, y usan sub-llamadas para resumir secciones — todo de forma autónoma.
El paper muestra que los RLM procesan entradas hasta dos órdenes de magnitud más allá de la ventana de contexto, con mejoras de ~28% sobre los modelos base.
Arquitectura del prototipo
El prototipo tiene tres componentes:
1. El Orquestador
Un bucle por turnos que gestiona la conversación entre el LLM y el entorno Python:
for turn in range(1, max_turns + 1):
response = client.chat(
messages=messages,
tools=[python_exec, final],
tool_choice="auto",
)
# Procesar tool calls, recoger observaciones
# Parar cuando el modelo llame a "final"El LLM tiene acceso a dos herramientas:
python_exec(code): Ejecutar código Python en un entorno persistentefinal(answer): Devolver la respuesta sintetizada
2. El Entorno Python Persistente
El documento completo se carga como un string en la variable context en un entorno Python que persiste entre turnos. Helpers integrados:
context # El texto completo del documento (~4M chars)
context_len # Longitud
get_slice(start, end) # Extraer un substring
search(pattern, max_results=5) # Búsqueda regex con snippets de contexto
llm_query(prompt_text) # Sub-llamada al LLM para análisis de fragmentosEl crítico es llm_query(). Cuando el modelo encuentra un fragmento relevante, puede invocar una llamada separada al LLM para resumir o analizar solo ese fragmento — esta es la parte recursiva.
3. La API LLM
Azure OpenAI con GPT-5 vía tool calling. El system prompt le dice al modelo que es un RLM y que el documento NO está en su contexto:
Eres un RLM (Recursive Language Model). El documento completo NO está en tu contexto.
El texto está cargado en un entorno Python como variable `context`.
Usa python_exec para explorarlo con slicing y búsqueda.
Usa llm_query() para sub-consultas sobre fragmentos.
Llama a `final` con tu respuesta cuando estés listo.Construyendo la demo: Paso a paso
1. Setup
git clone https://github.com/JaviMaligno/rlm-prototipo
cd rlm-prototipo
uv venv && source .venv/bin/activate
uv pip install -e .
cp .env.example .env
# Rellena tus credenciales de Azure OpenAI2. Recopilar datos (~1M tokens)
Escribí un script que descarga papers de arXiv y extrae texto limpio de las fuentes LaTeX:
python scripts/fetch_arxiv.py --target-chars 4000000 --output-dir dataBusca papers sobre agentes LLM, RAG e IA — priorizando la extracción de fuentes LaTeX (texto más limpio), con fallback a PDF-a-texto, y usando abstracts como último recurso. Se detiene cuando alcanza el objetivo de caracteres.
En unos 2 minutos, descargó 71 papers totalizando 4,033,636 caracteres (~1M tokens).
3. Ejecutar el RLM
rlm run \
--input "data/*.txt" \
--question "¿Cuál es la contribución principal de estos papers? \
Resume las 5 temáticas más frecuentes."
# Defaults: --max-turns 15 --max-subcalls 90Qué ocurre durante la ejecución
Observar el RLM trabajar es fascinante. Este es el comportamiento real sobre nuestro corpus de 71 papers:
Turno 1: El modelo comprueba el tamaño del documento, identifica la estructura, y muestrea fragmentos representativos:
L = len(context) # → 4,044,992
starts = [0, L//3, 2*L//3] # Muestrear 3 posiciones
for st in starts:
frag = context[st:st+6000]
topics = llm_query(f"Extrae 4-6 temas clave:\n{frag}")Turno 2: Con los temas iniciales recopilados, sintetiza la respuesta final:
synth = llm_query(f"De estas listas parciales, identifica los 3 temas principales:\n{joined}")Con un budget pequeño (15 subcalls), el modelo completa en 2 turnos, menos de 1 minuto — muestreando estratégicamente y produciendo una síntesis coherente sin ver nunca el millón completo de tokens.
Con budget completo (90 subcalls), el modelo analiza los 71 papers individualmente en ~23 minutos, produciendo una síntesis detallada que cita títulos específicos de papers, métodos y métricas. Usó 80 subcalls para análisis y el resto para síntesis — todo con un 100% de tasa de éxito.
Gestión de presupuesto: La decisión de diseño clave
El reto de ingeniería más interesante no fue la arquitectura — fue la gestión de recursos. Cuando el modelo tiene subcalls limitadas repartidas entre múltiples turnos, ¿cómo debe distribuirlas?
El problema
Con 71 papers pero solo 15 subcalls, el enfoque naíf falla:
# MAL: El modelo intenta iterar sobre todo
for section in sections: # 71 secciones
llm_query(section[:8000]) # Quema todas las subcalls en el turno 1
# ¡No quedan subcalls para la síntesis!Visibilidad del budget: Enseñando al modelo a autoplanificarse
La solución fue inyectar la info de budget restante en cada resultado de herramienta:
[budget] subcalls restantes: 11/15 | turnos restantes: 4/5Esta simple adición transforma el comportamiento del modelo. En lugar de iterar exhaustivamente, aprende a muestrear fragmentos representativos y reservar subcalls para la síntesis.
Benchmark: Budget global vs Relleno por turno
Probé dos estrategias con parámetros idénticos (5 turnos, 15 subcalls):
| Budget global + Info visible | Relleno por turno | |
|---|---|---|
| Tiempo | 3:56 | 1:31 (sin respuesta) |
| Subcalls usadas | 9 | 2 |
| Resultado | 3 temas con explicaciones | ”Max turns reached” |
| Comportamiento | Muestreó, hizo fallback a búsqueda por keywords cuando fallaron subcalls, sintetizó | Gastó 3 turnos explorando sin usar subcalls, luego falló |
El budget global gana claramente. El enfoque de relleno por turno elimina la urgencia — el modelo “vagabundea” explorando sin comprometerse con subcalls. Con budget global y un contador de recursos restantes visible, el modelo planifica su estrategia alrededor de los recursos disponibles.
El modelo con budget global también mostró mejor adaptabilidad: cuando las llamadas a llm_query() devolvieron respuestas vacías (un problema de GPT-5), hizo fallback autónomo a conteo de keywords con search() — sin necesidad de subcalls.
Resultados y lecciones aprendidas
Lo que funcionó
El RLM analizó exitosamente 71 papers e identificó temáticas coherentes en múltiples ejecuciones:
- Seguridad, ética y robustez — alineamiento, mitigación de sesgos, resistencia adversarial
- LLMs y NLP a escala — mejoras en Transformers, prompting, razonamiento de contexto largo
- Aplicaciones transversales de IA — salud, robótica, generación de código, sistemas multimodales
Problemas de compatibilidad con GPT-5
Construir contra GPT-5 requirió varios fixes:
max_completion_tokensen vez demax_tokens(renombrado del parámetro de la API)- Sin
temperaturepersonalizada — GPT-5 solo soporta el valor por defecto (1) - Serialización de tool calls — los objetos del SDK necesitaban conversión explícita a dicts para el historial de mensajes
- Rechazo de
tools=null— GPT-5 devuelve contenido vacío cuandotoolsytool_choicese establecen explícitamente a null; estos params deben omitirse
La trampa de los reasoning tokens
Este fue el bug más difícil de diagnosticar. Las sub-llamadas devolvían content: null el 100% de las veces. La API no estaba caída — respondía con finish_reason: "length" y consumía todos los tokens internamente.
GPT-5 es un modelo de razonamiento (como o1/o3). El parámetro max_completion_tokens incluye tanto los tokens de razonamiento interno como la respuesta visible. Con max_completion_tokens=800, el modelo gastaba los 800 tokens “pensando” y le quedaban cero para la respuesta real:
finish_reason: length
content: ""
reasoning_tokens: 800 ← todo el budget consumido aquí
completion_tokens: 800 ← nada para la respuesta visibleLa solución fue subir max_completion_tokens de 800 a 8000 para las sub-llamadas. Esto da al modelo ~2000-3000 tokens para razonar y deja de sobra para la respuesta visible (~500-1000 chars).
El resultado fue drástico: la tasa de éxito de sub-llamadas pasó de ~6% a 100% (80/80 en nuestro test). Lo que habíamos atribuido a “problemas intermitentes de la API” era en realidad un problema sistemático de starvation de recursos.
Guardrails que importan
Tres guardrails previnieron los modos de fallo más comunes:
-
Límite de longitud de código (50 líneas máx): Sin esto, el modelo escribe parsers regex enormes en vez de usar
llm_query(). Al rechazar el código, hace fallback a código simple y correcto. -
Hints de error específicos: En vez de un genérico “ocurrió un error”, el sistema da guía concreta:
SyntaxError→ “Simplifica tu código. Usa llm_query() en vez de parsing complejo.”Max subcalls reached→ “Sintetiza con los datos que ya tienes y llama a final.”
-
Inyección de budget: Las subcalls/turnos restantes mostrados tras cada resultado de
python_execcambiaron el comportamiento del modelo de “iterar todo” a “muestrear estratégicamente”.
Auto-corrección en acción
Uno de los comportamientos emergentes más interesantes: el modelo escribe código con bugs, recibe el error, y lo corrige autónomamente. Un ejemplo real:
# Turno 3: El modelo intenta hacer slicing sobre un dict como si fuera lista
KeyError: slice(None, 120, None)
# Turno 4: El modelo ve el traceback, se da cuenta de su error,
# y reescribe el código usando indexación de listasEl modelo también se auto-corrige a un nivel más alto. En una ejecución, encontró solo 5 separadores de archivo en vez de 71 porque buscó el patrón incorrecto. Al ver el conteo inesperado en el output, probó un enfoque diferente y encontró todos los archivos.
Esto no es un bug — es el sistema funcionando como fue diseñado. El loop agentic devuelve cada error al modelo como una observación, y el modelo aprende de ello dentro de la misma ejecución. Los guardrails (límite de código, hints de error, visibilidad de budget) mantienen estos ciclos de auto-corrección cortos y productivos.
Streaming de output en tiempo real
Un fix sutil pero crítico: el entorno Python usa redirect_stdout durante la ejecución de código, lo que captura todo el output — incluyendo los logs de progreso de subcalls del orquestador. La solución fue anclar Rich Console al sys.stdout real en tiempo de construcción:
# Console(file=sys.stdout) guarda una referencia directa al stdout real.
# Cuando redirect_stdout luego cambia sys.stdout a StringIO, la Console
# sigue escribiendo al terminal original.
self.console = Console(file=sys.stdout)Sin esto, los usuarios observando el terminal durante bloques largos de python_exec no verían nada hasta que la ejecución completa termine — mala UX para ejecuciones de 5+ minutos.
Trade-offs
| Aspecto | RLM | RAG | Contexto largo |
|---|---|---|---|
| Complejidad de setup | Baja (sin embeddings, sin vector DB) | Media-Alta | Baja |
| Contexto global | Alto (el modelo explora libremente) | Bajo (el retrieval decide) | Alto |
| Coste | Alto (múltiples llamadas API por consulta) | Bajo por consulta | Medio |
| Latencia | Alta (turnos secuenciales + subcalls) | Baja | Media |
| Tamaño máx. documento | Ilimitado (out-of-core) | Ilimitado | Limitado por ventana |
RLM brilla cuando necesitas análisis profundo y exploratorio de documentos masivos donde no sabes de antemano qué es relevante. RAG es mejor para recuperación de patrones conocidos a escala. El contexto largo funciona cuando el documento cabe.
Cuándo usar RLM
Usa RLM cuando:
- Tu documento excede la ventana de contexto y necesitas comprensión global
- Necesitas que el modelo decida qué leer (preguntas exploratorias)
- Quieres transparencia — puedes ver exactamente qué código escribe el modelo
No uses RLM cuando:
- Tienes un patrón de recuperación simple (usa RAG)
- La latencia importa más que la profundidad (RLM es secuencial)
- El documento cabe en contexto (usa contexto largo directamente)
Fase 2: De prototipo a producción
La primera versión funcionaba, pero tenía ineficiencias claras: el modelo gastaba 2-3 turnos parseando la estructura del documento, las sub-llamadas se ejecutaban secuencialmente (~10-25s cada una), y el modelo no tenía conocimiento previo de los archivos disponibles. Tres mejoras dirigidas cambiaron esto.
1. Helpers de estructura
En vez de dejar que el modelo descubra los límites de los archivos parseando separadores ===== FILE: manualmente, ahora pre-computamos un índice de archivos al cargar y exponemos helpers estructurados:
file_count # → 71
list_files() # → [{index: 0, name: "paper1.txt", start: 0, end: 56234, size: 56200}, ...]
get_file(i) # → texto completo del archivo iEsto elimina la fase de exploración por completo. El modelo ya no necesita search("===== FILE:") ni contar separadores — sabe exactamente cuántos archivos hay y puede leer cualquiera directamente.
2. Tabla de contenidos inyectada
El primer mensaje del usuario ahora incluye una tabla de contenidos auto-generada:
## Tabla de Contenidos (71 archivos, 4,044,992 chars)
[0] 2501.12345_paper_title.txt (56,200 chars)
[1] 2501.23456_another_paper.txt (48,100 chars)
...
[70] 2502.99999_last_paper.txt (61,300 chars)
Usa `get_file(i)` para leer el archivo i. Usa `list_files()` para ver detalles.Combinado con el system prompt actualizado, el flujo recomendado del modelo cambia de “explorar → descubrir → muestrear → sintetizar” a “leer TOC → analizar en batch → sintetizar”.
3. Sub-llamadas en paralelo
La mayor ganancia en latencia. Una nueva función llm_query_batch() ejecuta múltiples sub-llamadas concurrentemente usando ThreadPoolExecutor:
# Antes: bucle secuencial (~10s × 71 = ~12 min)
for i in range(file_count):
results.append(llm_query(f"Resume:\n{get_file(i)[:6000]}"))
# Después: batch paralelo (~10s × 71 / 5 workers = ~3 min)
prompts = [f"Resume:\n{get_file(i)[:6000]}" for i in range(file_count)]
results = llm_query_batch(prompts, max_workers=5)La implementación gestiona el conteo thread-safe de subcalls (via threading.Lock), valida el budget antes de arrancar, devuelve resultados en el orden de entrada, y captura fallos individuales como strings [error: ...] sin abortar el batch completo. Si el batch excede el budget restante, procesa tantos prompts como quepan y marca el resto como [skipped] — sin turnos desperdiciados en errores.
4. El agujero negro de exec()
Una regresión inesperada casi descarrila la Fase 2. exec() de Python no muestra automáticamente los valores de las expresiones — a diferencia de un REPL interactivo. Con el enfoque multi-turno de la Fase 1 esto no importaba, porque el modelo acumulaba resultados entre turnos. Pero el enfoque batch de la Fase 2 lo computa todo en un solo python_exec: el modelo analizó los 71 papers, los sintetizó en una variable final_text… y recibió stdout: 0 chars. El resultado se evaporó.
Peor aún: cuando el modelo respondió con texto plano (¡tenía la respuesta!), el guardrail lo redirigió a python_exec — pero con cero subcalls restantes el modelo no podía usar llm_query(), así que se quedó en un bucle infinito hasta agotar los turnos.
Dos fixes:
-
Auto-captura de la última expresión (como IPython):
PythonEnv.exec()ahora usaastpara detectar si la última sentencia es una expresión, la separa del cuerpo, la evalúa coneval()por separado, y añade el resultado a stdout. El modelo ya no necesita saber nada sobreprint()— simplemente funciona. -
Nudge consciente del budget: Cuando las subcalls se agotan y el modelo responde con texto, el nudge ahora dice “Llama a
final(answer=...)AHORA con los datos que tienes” en vez de redirigir apython_exec.
5. Truncamiento de la síntesis
Otro problema sutil: el modelo delegaba la síntesis a una sub-llamada llm_query(), pasando los 71 resúmenes (~42K chars) como prompt. Pero las sub-llamadas tienen un límite de 6K caracteres para controlar costes — así que la síntesis solo veía los archivos [0]-[7] y no citaba nada más allá.
La solución: indicar al modelo que sintetice localmente en python_exec usando los resultados del batch que ya tiene en memoria, en vez de delegarlo a otra llamada LLM. Los datos ya están ahí — no hace falta una sub-llamada.
Con estas cinco mejoras, la pregunta amplia pasó de 13 turnos / 22:53 a 2 turnos / 3:25 con cobertura completa 71/71. Pero quedaban más problemas.
6. Estrategia dual: preguntas amplias vs específicas
Hasta aquí, el sistema prompt obligaba una única estrategia: “lanza un batch con TODOS los archivos”. Eso funciona perfecto para preguntas amplias (“resume los 5 temas principales”), pero es un despilfarro para preguntas específicas (“¿qué vulnerabilidades identifica el paper agent-fence?”). El modelo gastaba 71 subcalls escaneando todo el corpus cuando solo necesitaba un archivo.
La solución: dos flujos explícitos en el system prompt:
- Flujo A (pregunta amplia): batch de todos los archivos, síntesis local,
final(). Sin cambios. - Flujo B (pregunta específica): identificar archivos relevantes por nombre en la TOC, leer el contenido COMPLETO con
get_file(i), dividir en chunks de ~30K caracteres con overlap, y lanzar subcalls focalizadas para extraer datos exactos.
Además, subimos max_subcall_prompt_chars de 6K a 32K — cuando el modelo necesita analizar un paper entero en profundidad, no debería truncar al 20% del texto.
7. Nudge de síntesis: el problema del turismo exploratorio
Incluso con la instrucción “no desperdicies turnos” en el prompt, el modelo la ignoraba. Tras hacer sus subcalls, en vez de sintetizar y llamar final(), lanzaba rondas de search() y get_file() buscando “más datos” hasta agotar los 15 turnos.
La solución fue estructural, no verbal: un mecanismo de nudge de síntesis en el orquestador. Tras cada turno con tool calls, el sistema compara el contador de subcalls con el del turno anterior. Si pasan 3 turnos consecutivos sin nuevas subcalls (solo python_exec con search() o lectura), inyecta un mensaje forzado:
“PARA. Ya tienes suficientes datos. Sintetiza lo que tienes y llama
final(answer=...)EN EL SIGUIENTE turno.”
Esto cortó el “turismo exploratorio” de raíz. El modelo ahora sintetiza inmediatamente tras el nudge.
8. max_tokens para respuestas largas
El modelo a veces decía “el mensaje completo supera el límite y se trunca, ¿lo divido en partes?” en vez de llamar final(). La causa: max_tokens=4096 en el bucle principal del orquestador — los argumentos de tool calls largos se truncaban. Subimos a 16384 (igual que el grace turn).
Antes vs Después (actualizado)
| Métrica | Fase 1 | Fase 2 | Fase 2.5 (amplia) | Fase 2.5 (específica) |
|---|---|---|---|---|
| Turnos | 13 | 2 | 5 | 12 |
| Tiempo | 22:53 | 3:25 | 4:13 | 3:22 |
| Subcalls | 80 | 71 | 71 | 8 |
| Cobertura | ~50/71 | 71/71 | 71/71 | 1 paper en profundidad |
La pregunta amplia tarda un poco más que el mejor caso de Fase 2 (el modelo usa más turnos para sintetizar con prompts de 25K en vez de 6K), pero la calidad de los resúmenes es notablemente mayor. La pregunta específica es un caso de uso completamente nuevo: antes era imposible extraer datos detallados de un paper concreto sin desperdiciar todo el budget en el batch de 71.
Demo en vídeo
Logs de ejecución
Flujo A — pregunta amplia: "¿Cuál es la contribución principal? Resume las 5 temáticas más frecuentes" (click para expandir)
──────────────────── Turn 1/15 subcalls=0/90 elapsed=0:00 ────────────────────
LLM responded in 26.5s — content=False tool_calls=1
╭────────────────────────── python_exec (38L) 0:26 ───────────────────────────╮
│ files = list_files() │
│ prompts = [] │
│ for f in files: │
│ text = get_file(f['index']) │
│ chunk = text[:25000] │
│ prompts.append( │
│ "Resume en 1-2 frases la contribución principal del paper..." │
│ + chunk │
│ ) │
│ results = llm_query_batch(prompts, max_workers=5) │
│ # ... clasificación por categorías y síntesis local ... │
╰──────────────────────────────────────────────────────────────────────────────╯
⤷ llm_query_batch: 71 prompts, max_workers=5 (0:26)
⤷ llm_query #1/90 (0:26) 25219ch — Resume en 1-2 frases la contribución...
⤷ llm_query #2/90 (0:26) 25219ch — Resume en 1-2 frases la contribución...
...
⤷ llm_query #71/90 (3:05) 25219ch — Resume en 1-2 frases la contribución...
✓ 6.9s — 530 chars
✓ 8.9s — 548 chars
✓ 11.2s — 630 chars
✓ 25.8s — 720 chars
✓ batch done 182.9s — 71/71 succeeded
ok exec=182.9s stdout=13650ch stderr=0ch
╭──────────────────────── python_exec result (ok=True) ────────────────────────╮
│ {'summary': [('Evaluación y benchmarks de agentes', 25), │
│ ('Seguridad, robustez y cumplimiento', 19), │
│ ('Coordinación y razonamiento multi-agente', 13), │
│ ('Planificación, memoria y tareas de largo horizonte', 9), │
│ ('Aplicaciones científicas, salud y dominios especializados', 5)]} │
╰──────────────────────────────────────────────────────────────────────────────╯
[Turnos 2-3: síntesis local con categorías y ejemplos concretos]
─────────────────── Turn 5/15 subcalls=71/90 elapsed=4:08 ────────────────────
2 text responses — accepting as final answer
╭──────────────────────────────── Final Answer ────────────────────────────────╮
│ Analicé 71 papers. Las 5 temáticas más frecuentes: │
│ - Evaluación y benchmarks de agentes (25 papers) │
│ • ScratchWorld: benchmark de 83 tareas para agentes GUI multimodales │
│ • PABU: actualización de creencias, 81% éxito, −26.9% pasos │
│ - Seguridad, robustez y cumplimiento (19 papers) │
│ • AutoElicit: elicita comportamientos inseguros en agentes computer-use │
│ • SCOUT-RAG: traversal progresivo en Graph-RAG, reduce coste │
│ - Coordinación y razonamiento multi-agente (13 papers) │
│ • ICA: credit assignment visual vía GRPO, supera baselines │
│ • RAPS: coordinación pub-sub con reputación bayesiana │
│ - Planificación, memoria y largo horizonte (9 papers) │
│ - Aplicaciones científicas y salud (5 papers) │
╰──────────────────────────────────────────────────────────────────────────────╯
Completed in 4:13 — 5 turns, 71 subcallsFlujo B — pregunta específica: "¿Qué vulnerabilidades identifica el paper agent-fence?" (click para expandir)
──────────────────── Turn 1/15 subcalls=0/90 elapsed=0:00 ────────────────────
╭──────────────────── python_exec (5L) 0:10 ─────────────────────╮
│ # Flujo B: lee el archivo completo del paper identificado │
│ text = get_file(13) # ← agent-fence, identificado por TOC │
│ len(text) # → 32037 chars │
╰─────────────────────────────────────────────────────────────────╯
──────────────────── Turn 2/15 subcalls=0/90 elapsed=0:10 ────────────────────
╭────────────────────────── python_exec (13L) 0:18 ───────────────────────────╮
│ # Divide en chunks de 20K con overlap y lanza batch │
│ chunks = [text[i:i+25000] for i in range(0, len(text), 20000)] │
│ prompts = [ │
│ "Extrae los 14 tipos de ataques definidos en Agent-Fence " │
│ "con nombres exactos. Extrae MSBR por arquitectura.\n" + c │
│ for c in chunks │
│ ] │
│ results = llm_query_batch(prompts) │
╰──────────────────────────────────────────────────────────────────────────────╯
⤷ llm_query_batch: 2 prompts, max_workers=5 (0:18)
⤷ llm_query #1/90 (0:18) 25384ch — Extrae los 14 tipos de ataques...
⤷ llm_query #2/90 (0:18) 12421ch — Extrae los 14 tipos de ataques...
✓ 26.0s — 223 chars
✓ 34.4s — 206 chars
✓ batch done 34.4s — 2/2 succeeded
──────────────────── Turn 4/15 subcalls=3/90 elapsed=1:05 ────────────────────
# Envía el paper completo (32015ch) en una sola subcall para confirmar
⤷ llm_query #3/90 (1:05) 32015ch — Lee el paper Agent-Fence y extrae...
✓ 31.2s — 640 chars
╭──────────────────────── python_exec result (ok=True) ────────────────────────╮
│ 1) Tipos de ataques (nombres exactos): │
│ 1. Denial-of-Wallet 2. Authorization Confusion │
│ 3. Retrieval Poisoning 4. Planning-Layer Manipulation │
│ 5. Tool-Use Hijacking 6. Objective Hijacking 7. Delegation Attacks │
│ 8. prompt/state injection 9. retrieval/search poisoning │
│ 10. delegation abuse 11. Unauthorized Tool Invocation (UTI) │
│ 12. Unsafe Tool Argument (UTA) 13. Wrong-Principal Action (WPA) │
│ 14. State/Objective Integrity Violation (SIV) │
│ │
│ 2) MSBR por arquitectura: │
│ - LangGraph: 0.29 ± 0.04 │
│ - AutoGPT: 0.51 ± 0.07 │
╰──────────────────────────────────────────────────────────────────────────────╯
[Turnos 5-8: search() exploratorio sin nuevas subcalls]
──────────────────── Turn 9/15 ────────────────────────────────────────────────
⚠ 3 turns without new subcalls — nudging to call final()
──────────────────── Turn 10/15 subcalls=8/90 elapsed=3:13 ──────────────────
# Sintetiza inmediatamente tras el nudge
╭─────────────────────── python_exec result (ok=True) ───────────────────────╮
│ Vulnerabilidades y tipos de ataques (14 clases definidas por Agent-Fence): │
│ 1. Denial-of-Wallet 2. Authorization Confusion │
│ 3. Retrieval Poisoning 4. Planning-Layer Manipulation │
│ 5. Delegation Attacks 6. Objective Hijacking 7. Tool-Use Hijacking │
│ 8. prompt/state injection 9. retrieval/search poisoning │
│ 10. delegation abuse 11. Unauthorized Tool Invocation (UTI) │
│ 12. Unsafe Tool Argument (UTA) 13. Wrong-Principal Action (WPA) │
│ 14. State/Objective Integrity Violation (SIV) │
│ │
│ MSBR por arquitectura: LangGraph 0.29±0.04 — AutoGPT 0.51±0.07 │
╰────────────────────────────────────────────────────────────────────────────╯
───────────────────────────────── Final Answer ─────────────────────────────────
Completed in 3:22 — 12 turns, 8 subcallsNota: el paper original cita 8 arquitecturas evaluadas, pero el texto extraído de PDF solo contiene datos MSBR explícitos para LangGraph y AutoGPT. Las tablas con las 8 arquitecturas probablemente estaban en formato imagen/tabla LaTeX y no sobrevivieron la conversión a texto plano.
Próximos pasos
Mejoras pendientes para producción:
- Caché de resultados entre ejecuciones para consultas repetidas sobre el mismo corpus
- Tracking de costes por consulta para presupuestos de producción
El código fuente completo está disponible en el repositorio de GitHub.
Basado en el paper “Recursive Language Models”. Construido con Azure OpenAI GPT-5 y Python.