
Hace poco publiqué Science Catch-Up — un ensayo de 16 capítulos que examina los límites del método científico y propone un marco para evaluar el conocimiento sin esperar al consenso. El ensayo completo se escribió con asistencia de inteligencia artificial: primero con OpenAI Codex (GPT 5.2/5.3), luego con Claude Code (Opus 4.5/4.6).
La diferencia de calidad fue llamativa. No de la forma que esperarías de una comparación de generación de código — sino en el terreno mucho más exigente de la prosa.
El ensayo está disponible en Payhip (español) y Payhip (inglés).
El proyecto
Science Catch-Up no es una lectura ligera. Es un ensayo combativo, con abundantes referencias, que critica el cientifismo como estructura de poder, traza el coste del dogma institucional y propone criterios operativos para evaluar el conocimiento informal. El tono tenía que ser preciso: directo sin ser conspiranoico, crítico sin ser anti-ciencia, y provocador sin convertirse en panfleto.
Ese nivel de matiz es exactamente donde la escritura con IA se pone a prueba — y donde las diferencias entre herramientas se vuelven imposibles de ignorar.
Fase 1: Codex (GPT 5.2/5.3) — el arranque difícil
Los primeros borradores se escribieron con OpenAI Codex. La estructura inicial y los capítulos tomaron forma, pero los problemas se acumularon rápido.
Los mensajes de commit verbosos y repetitivos cuentan la historia. Compara los commits tempranos de la era GPT:
“Se amplía la sección sobre biohacking, clarificando las categorías de restauración, mitigación y deuda biológica. Se añaden ejemplos prácticos para cada tipo y se enfatiza la distinción entre restaurar, mitigar y endeudarse, mejorando la comprensión del impacto fisiológico de estas prácticas.”
Con los commits posteriores de la era Opus:
“fix: QA polish — glossary term, font consistency, cover in PDF, new food pyramid”
Mismo repositorio, mismo autor, distinta herramienta. Los mensajes de commit reflejan la prosa misma.
Los problemas específicos de la escritura de GPT:
- Expresiones repetitivas por todas partes. Palabras como “precisamente”, “en el fondo” y aperturas de sujeto repetidas (“Science Catch-Up propone…”, “El marco establece…”) aparecían en clusters. Al final tuve que hacer una pasada dedicada de limpieza — commit
61684f4: “Limpiar patrones repetitivos ChatGPT: precisamente, sujetos repetidos, en el fondo”. - El patrón “Ejemplo:”. GPT insertaba consistentemente la etiqueta “Ejemplo:” antes de los casos ilustrativos, incluso cuando los criterios editoriales decían explícitamente que los ejemplos debían integrarse con prosa fluida (“Por ejemplo…”, “En la práctica…”). Este formato rígido fue de lo más difícil de eliminar porque reaparecía constantemente.
- Tono blando y conciliador. El ensayo necesitaba ser combativo y directo. GPT suavizaba las aristas, añadía disclaimers (“esto no es anti-ciencia”), y producía lo que parecía una versión academizada de ideas que originalmente eran afiladas y provocadoras.
Fase 2: Claude Code (Opus 4.5/4.6) — otra liga
Cuando cambié a Claude Code con Agent Teams, la mejora fue inmediata. La prosa era más natural, el tono más cercano a lo que buscaba, y la adherencia a las directrices editoriales mucho más fuerte.
Tras varias iteraciones, creé un documento formal de criterios editoriales — cubriendo tono, estructura argumental, cómo manejar ejemplos (tres criterios con nombre para estilos narrativo, esquemático e híbrido), estándares de referencia y la dirección retórica del ensayo. Claude Code siguió estos criterios de forma consistente una vez establecidos.
Lo que Claude Code hizo bien:
- Adherencia al tono. La voz combativa y sin disculpas salía de forma natural. Menos hedging defensivo, más argumentación directa.
- Inteligencia estructural. Dado un esquema de capítulo y criterios editoriales, producía contenido que respetaba el flujo y construía sobre las secciones anteriores.
- Investigación y referencias. Excelente encontrando e integrando fuentes relevantes, formateando entradas bibliográficas y manteniendo la consistencia entre capítulos.
- Gramática y ortografía. Esencialmente impecable tanto en español como en inglés — una ventaja nada trivial para una publicación bilingüe.
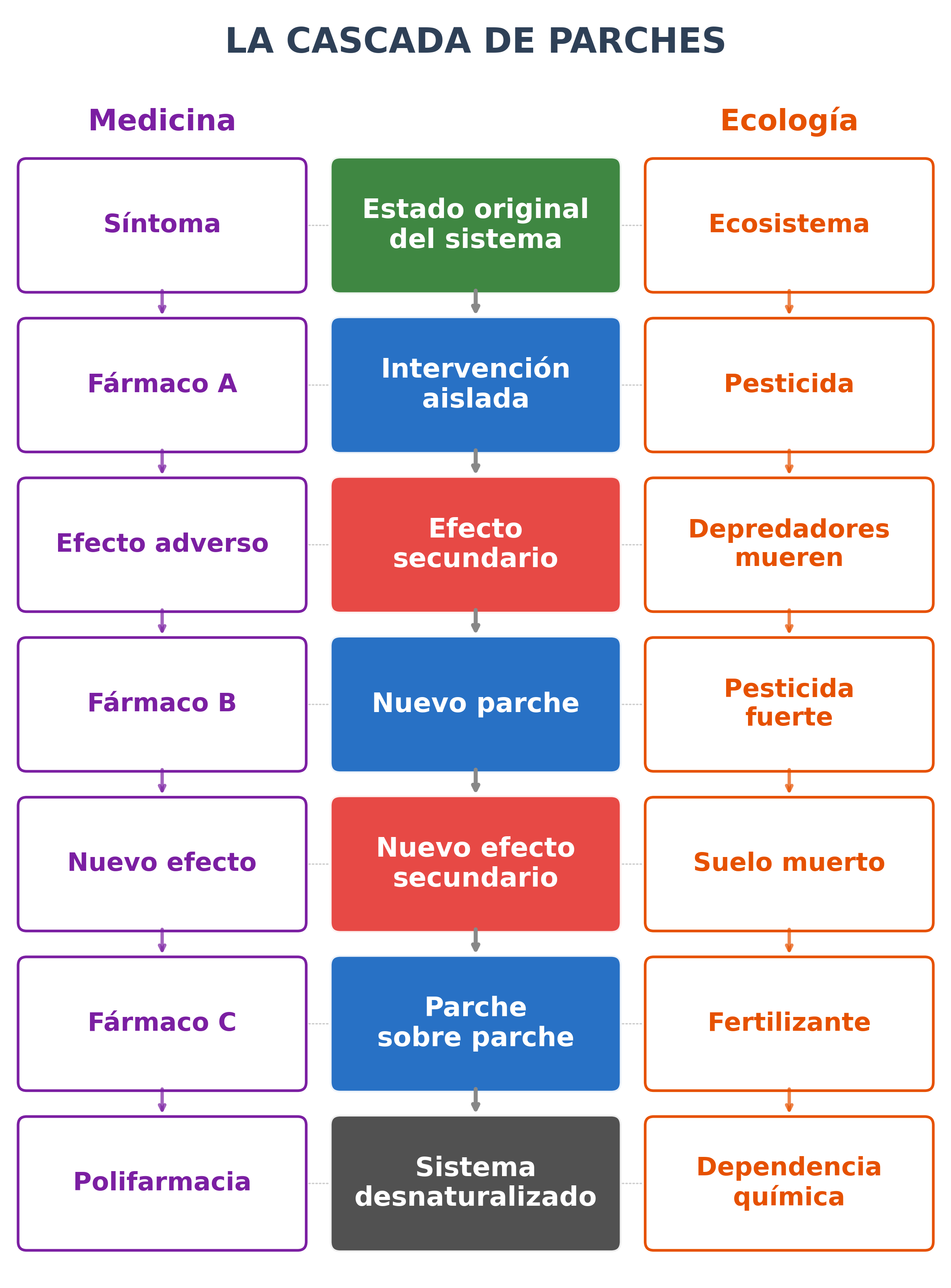
- Figuras programáticas. La mayoría de los diagramas y gráficos del ensayo fueron generados por Claude Code con scripts de matplotlib — la pirámide de evidencia, el ciclo de Science Catch-Up, el diagrama de cascada de parches. Solo una figura y la portada se crearon con Gemini.
Donde todavía se quedó corto:
- Pérdida de contexto en subagentes. Al despachar múltiples subagentes en paralelo (un patrón habitual con Agent Teams), los agentes individuales a veces escribían secciones de forma aislada, perdiendo el hilo narrativo o produciendo contenido que no fluía con los capítulos adyacentes. El resultado leía como si autores distintos hubieran escrito párrafos contiguos.
- Sigue necesitando revisión a fondo. Incluso con la mejor calidad de Claude Code, revisé y corregí cada párrafo. Las ideas y las instrucciones eran mías; el rol de la IA fue transformar ideas en bruto en contenido desarrollado, proponer estructura e investigar. Estimo que el 95%+ del texto fue estrictamente escrito por IA, pero cada frase fue validada o ajustada por mí.
Prosa vs código: por qué escribir es más difícil
Este proyecto cristalizó algo que venía intuyendo: la prosa asistida por IA requiere más supervisión que el código asistido por IA.
En código, la funcionalidad es lo primero. Si una función funciona, pasa los tests y maneja los casos límite, el estilo importa pero es secundario. La modularidad, las convenciones de nombrado y la calidad del código son todavía más fáciles de lograr y verificar que sus equivalentes en prosa.
En prosa, qué dices y cómo lo dices son inseparables. Un párrafo que comunica la idea correcta pero de forma blanda, evasiva o repetitiva es un fracaso — aunque la “funcionalidad” (transmitir información) funcione. No hay test suite para el tono. No hay linter para la fuerza retórica. No hay pipeline de CI que detecte “esto suena como si lo hubiera escrito ChatGPT”.
Me encontré dedicando mucho más tiempo a revisar prosa del que jamás dedico a revisar código generado por IA. Cada frase tenía un peso que una línea de código no tiene.
La prueba de la traducción
El ensayo se escribió originalmente en español. La traducción al inglés se hizo con Claude Code y fue notablemente rápida — la estructura, las referencias y el formato se trasladaron limpiamente.
Los retos interesantes fueron culturales, no técnicos:
- Las frases con gancho necesitaban adaptación, no traducción literal. Remates que funcionaban en español a veces requerían un replanteamiento completo en inglés.
- Siglas de dominio: el ensayo introduce CSV (Ciencias de Sistemas Vivos) y CSI (Ciencias de Sistemas Inertes) en español. En inglés se convirtieron en OSS (Organic System Sciences) e ISS (Inert System Sciences) — una decisión deliberada que requirió discusión.
El proceso iterativo
Algo que vale la pena destacar: la escritura nunca fue un proceso de una sola pasada. El ciclo típico era:
- Borrador — la IA escribe una primera versión razonable a partir de mi esquema y notas
- Surgen ideas — leer el borrador dispara nuevos pensamientos, ángulos que faltan, referencias adicionales
- Expandir — alimentar eso de vuelta, pedir adiciones específicas o reestructuración
- Revisar — detectar desviaciones de tono, patrones repetitivos, argumentos débiles
- Pulir — pasada final de consistencia con los criterios editoriales
Este ciclo ocurría por capítulo y a lo largo de todo el ensayo. La IA es extraordinaria en los pasos 1 y 3 — transformar ideas en bruto en contenido desarrollado. Pero los pasos 2, 4 y 5 siguen siendo fundamentalmente humanos.
El resultado
Más allá del ensayo en sí, el pipeline asistido por IA produjo:
- PDF y ePub en ambos idiomas
- Formato Amazon KDP con generación programática de portada
- Audiolibros en ambos idiomas usando el TTS Aoede de Google
- Metadatos de publicación para múltiples plataformas
El audiolibro en español ya está en Spotify. El de inglés viene en camino — haré posts separados para las ediciones en audiolibro.
Conclusiones
- Codex (GPT) produjo prosa notablemente peor — repetitiva, blanda y resistente a las directrices de estilo
- Claude Code (Opus) fue significativamente mejor — más cercano al tono deseado, mejor siguiendo criterios editoriales, mayor conciencia estructural
- Ninguno sustituye el juicio editorial — el bucle humano de revisar, repensar y refinar es innegociable para prosa de calidad
- La IA brilla en la transformación — convertir ideas en bruto en contenido estructurado, investigar referencias, manejar gramática y ortografía, generar figuras programáticamente
- La prosa requiere más supervisión humana que el código — porque estilo, tono y eficacia retórica no tienen tests automatizados
- La traducción fue la parte más fácil — la estructura se traslada limpiamente; solo los matices culturales y las frases con gancho necesitaron reflexión real
El ensayo es un trabajo serio y con opinión. Estés o no de acuerdo con su tesis, el proceso de escribirlo me enseñó más sobre creación asistida por IA que cualquier proyecto de código.
Science Catch-Up está disponible en Payhip (edición en español) y Payhip (edición en inglés).
¿Interesado en arquitecturas de agentes IA? Hablemos.